
Так кто же такие эти дата сайентисты? Baba Brinkman популярно объясняет, да еще и делает это в формате рэп-батла! Мы сделали вольный перевод. Смотрите, что получилось)
Привет! С вами Игорь Кузин, CEO в Smart Data Hub. Не так давно мы с коллегами наткнулись на видео Бабы Бринкмэна (реальное имя Дирк Мюрэй Бринкмэн), в котором он сравнивает подходы дейта сайентиста и классического статиста. Баба вообще и известен тем, что он читает рэп на тему науки.
Дата сайентист здесь такой модный и современный, а статист – это такой дедушка с бумажной бородой в олдовом костюме, что уже само по себе отражает характер противостояния между «наукой о данных» и классической статистикой.
Итак, давайте вместе с Бабой разберемся, кто же такой data scientist и чем же принципиально подход «науки о данных» отличается от обычной статистики? Поехали!
По итогам жеребьевки начинает МС слева. Дайте шума!
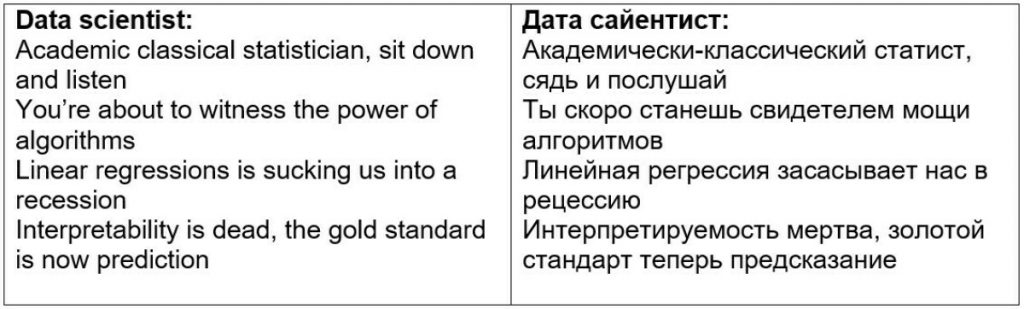
И дата сайентист сразу начинает с панча! Он говорит о том, что:
И вот на значимости предсказания давайте остановимся отдельно. Почему это так важно? Почему это, может быть, вообще самое важно в data science? Давайте разберемся!
Почему мы вообще анализируем статистику? Копаемся в данных, в срезах и метриках? Мы пытаемся понять, что эффективно, а что нет. В то, что эффективно, мы должны вкладывать больше ресурсов (обычно денег), а в то, что неэффективно, вкладывать меньше (урезать бюджет на такие сегменты). Это очень просто! Правда, есть деталь. Мы это делаем не потому, что нам очень интересно прошлое. Мы уверены в том, что в будущем будет примерно то же, что и в прошлом. Это называется «нативная модель прогнозирования», когда мы на будущие периоды экстраполируем попросту то, что было в прошлом. Обратите внимание: мы тоже прогнозируем! Просто вот так вот, по-простому, «нативно».
Но реальность в том, что в будущем может вовсе не быть так, как в прошлом! Для этого нам-то и нужно качественное прогнозирование. И для хорошего прогноза без ИИ в том или ином виде не обойтись.
Вангую: в будущем не будет систем аналитики в текущем виде, когда эти системы, по сути, являются системами статистики и визуализации. В будущем главным продуктом систем аналитики будут прогнозные данные, которые мы как раз-то на самом деле и хотим получить для оптимизации (часто даже сами того не осознавая).
Но вернемся к видео. Что же там дальше?

Статист наносит ответный удар! Он говорит о том, что дата сайентисты используют алгоритмы, работа которых сама по себе мало предсказуема и объяснима. Т.е. данные, по сути, закачиваются в некую «шайтан-машину», и на выходе получается некий результат. Что внутри этого «черного ящика», как именно он сработал, — до конца не известно. И как можно вообще опираться на такое «нечто», как понять, корректны ли выводы или нет?

Дайта сайентист отвечает, что может это и «черный ящик», но он дает точные ответы. Причем применим в абсолютно любых сферах жизни. И да, он не считает, что коробка «черная», она скорее «прозрачная», т.е. мы же сами и создаем те алгоритмы, которые будут отрабатывать в этой «коробке».
Тут статист подкалывает дата сайентиста. Типа, «ага, ну да, вы это все делаете с помощью прослеживаемой математики». Да, и действительно, математика «черного ящика» не всегда прослеживаема. Взять хотя бы известный метод кластеризации k-means. Ну он же, зараза, постоянно выдает разные данные на одном и том же массиве данных! Да, на самом деле, есть целая масса улучшенных вариаций k-means (например, «k-means++»), да и вовсе других методов кластеризации. Однако это вот как раз тот самый случай «непрослеживаемой математики».

МС справа, жги!

Да, есть такая проблема! Сейчас уже практически каждый может взять какую-то ML-библиотеку на python и сгенерить нечто. И без какого-то базового понимания принципов статистики это действительно похоже на некую форму невежества…

Какооой панч-лайн! Ну вот, коллеги нас и раскусили)) Спасибо Бабе за игру слов «data model» (модель данных) и «date a model» (встречаться с моделью).

Да и действительно, может и не так важно как именно это работает, если качество прогноза высокое? И может и не стоит бояться «черного ящика»? Ведь сама природа так же малообъяснима, как этот «черный ящик»?
Шум! Шум! Шум!

Ииии это панч! Да, в «науке о данных» есть немало нерешенных вопросов, но ведь она ох-как активно развивается! И с таким «дедушкиным» подходом никогда не достичь прорыва.
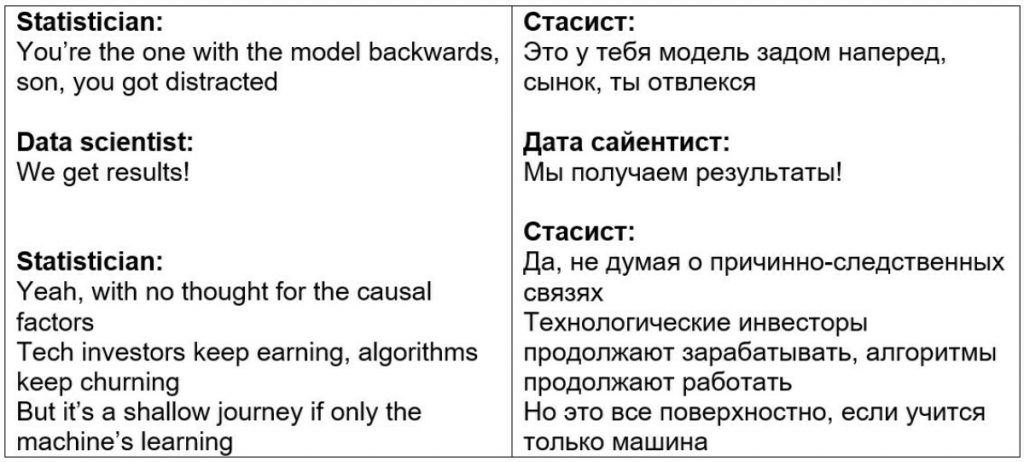

Статист опять за свое) Работать с «черным ящиком» — это поверхностно, говорит. А еще говорит, что нельзя пользоваться тем, что до конца не можешь осознать. А с ML-алгоритмами да-да, такое случается.
Далее вновь «припев»:

Спасибо Бабе за интересный формат! Ведь глубокий текст, и упакован в такую креативную обертку.
И да, в самом начале статьи я говорил о противостояния между «наукой о данных» и классической статистикой. На самом деле, по большому счету, пожалуй, ведь и нет никакого противостояния. Ведь «наука о данных» вбирает в себя всю классическую статистику, обогащая ее современными методами, основанными на активном использовании вычислительных машин. Но ведь говорить о противостоянии интереснее, не правда ли?
Материал был ранее опубликован на VC.RU
По разным данным от 30 до 70% рекламного бюджета самых разных компаний улетает "в трубу". Эти деньги можно сохранить или потратить на развитие бизнеса.


